一门安全课程的论文调研
考虑到个人主要还是对神经网络方面了解的比较多
因此对ai顶会中神经网络在恶意软件方面的论文进行了综述和分析
在这里记录一下
说不定以后还能用的上2333
在这个篇章中,我将简述恶意软件的范畴,历史事件,导致的影响和危害,重点将放在讨论神经网络在恶意软件检测中存在的问题。之后将以2007年关于软件动态检测方法的一篇论文为先导,阐述恶意软件检测的基本问题,最后将重点放在,恶意软件检测中使用神经网络模型后,实际的效果,以及后续产生的对抗样本问题,对目前顶会所提出的一些方法和应对措施进行讨论和分析。
从维基百科中我们可以获得最基础的恶意软件的定义,恶意软件,又称“流氓软件”,一般是指通过网络、便携式存储设备等途径散播的,故意对个人电脑、服务器、智能设备、电脑网络等造成隐私或机密数据外泄、系统损害(包括但不限于系统崩溃等)、数据丢失等非使用预期故障及信息安全问题,并且试图以各种方式阻挡用户移除它们,如同“流氓”一样的软件。恶意软件的形式包括二进制可执行档、脚本、活动内容等。
事实上,从互联网兴起之后,恶意软件的套路就层出不穷,严重者如wannacry先后攻击政府医院等机构的数据,如果七天内未进行付款数据就会被清楚,小到我们曾经经常遇到的浏览器劫持,都属于恶意软件的范畴,也正因为如此,恶意软件的应对成为了一个十分困难的问题。
首先,用户本身需要尽可能地提高警惕,恶意软件地最常见的传播腿精之一就是通过电子邮件,或者qq群等进行传播,比如有LOL幸运召唤师邮件,以及有一段时间高校群间流传的变声器程序。比如学校动漫社就有人恶意加群,发送这样的群邮件
这些情况只需要提高警惕避免访问和下载就可以避免,但是很多时候仅仅这样并不足以防范。有时候即使从合法网站下载有时也可能附加恶意软件,也因此我们需要使用合适的保护工具对恶意软件进行检测隔离。之前也提到了,恶意软件种类繁多,意图不一,如果想要有效隔离处理恶意软件,恶意软件检测自然就成为了保护工具最重要的一个环节。
恶意软件的检测方法可以简单被分为两大类,一类是动态分析,通过监视程序执行获得功能,如API,执行的指令,访问的IP地址等。为了进行动态分析,恶意软件必须在特殊的检测环境中运行,定制的虚拟机就是一个一种常见的选择。在这种情况下,恶意软件只能影响虚拟机。在2007年《Detecting System Emulators》就提出,这种方法的优势在于分析人员可以随时暂停系统并检查内存状态,还可以使用快照捕获特定时间点的系统状态,方便观察不同操作导致的效果,比如软件进程被杀死,删除注册表等等行为之后的系统状态。
但是这种方法会导致比较高昂的成本,同时也存在仿真环境不能完全模拟真实环境的问题。另一方面,随着恶意软件的开发水平不断提高,有的恶意软件会检测是否被分析,从而避免暴露其特征。比如,检测其代码是否在虚拟环境中执行,如果是,则相应调整程序行为。
另一种方法是静态分析方法,主要是通过分析程序指令和结构来确定功能,此时程序不是处于运行状态的。通过将可执行文件加载到反汇编程序(例如IDA)中,可以对恶意软件二进制文件进行逆向工程。 机器可执行代码可以转换为汇编语言代码,以便人类可以轻松阅读和理解。 然后,分析人员会着眼于该程序,以更好地了解它的功能以及程序要执行的操作。
在目前,单纯地依靠检测人员进行分析成本过高,用一些模型和规则进行检测,成为一种趋势。神经网络在图像处理和语义识别上都取得了优异的效果,神经网络可以有效提取高维特征,但是和许多其他机器学习模型一样,同样缺乏对抗敌手输入的鲁棒性。
在之前shamir教授在西电做分享的论文《A Simple Explanation for the Existence of Adversarial Examples with Small Hamming Distance》,就提到了很常见的MNIST数据集图象识别的问题,只需要修改3-4个像素点,就能成功让原本准确率高达99.35%的神经网络对数字进行错误分类。

在图像识别领域,即使存在鲁棒性问题,只有在特定情景,如自动驾驶等情境下会导致严重问题。但是在恶意软件检测领域,一旦被成功绕过检测,可能就会导致巨大损失。与此同时,制作图像的对抗样本只需要通过修改单个像素或者几个像素即可实现,并且不会影像数据本身,只有神经网络会因为这些扰动而误判,人类是可以正常进行分类的,如上图所示。但是在恶意程序识别中,制作对抗样本,在数据集中,如果这样随意地添加扰动会导致软件功能严重缺失或者增加,因此添加扰动需要更加谨慎且有效。
这里首先要明确一点,对抗样本的研究,并不是为了给图像分类或者恶意软件分类等任务制造麻烦,而是因为在实际过程中,可能会有客观或者主观的原因,造成了图像有畸变的像素点,恶意软件的静态分析出的参数产生了变化,如果不能很好地处理这种情况,那么神经网络的方法就会出现漏洞。因此想要让神经网络在恶意软件分类任务中实际应用,首先得有条件生成合适的对抗样本
在16年《Adversarial Perturbations Against Deep Neural Networks for Malware Classification》文中,作者对此进行了详细阐述,DREBIN数据集包含超过120000个Android应用程序示例,其实中包括5000多个恶意软件示例,其中包含静态分析方法所提取出的要素,如是否访问敏感数据,相机是否联网访问等。由于没有成熟公开的神经网络的恶意软件检测系统,自己写了一个分类器用于恶意软件识别,达到了97%的准确率,和当前用静态方法的其他模型水平相当。
作者在这之后就开始做对抗样本的研究,生成的对抗样本满足三个条件,完整添加或删除功能,不干扰原有的基本功能,添加数量有限的功能,伪代码如下:

看上去很复杂,逻辑其实还是比较简单的首先计算神经网络预测值为一个二维向量F[X],归一化之后根据两个值大小差距给出判断的置信度,比如【0.9,0.1】就能大概率判断其为正常软件,【0.5,0.5】就属于判断困难的软件,修改代表应用程序的功能参数X,将会导致输出的二维向量发生变化,在判断完修改各种功能参数的影响后,选择梯度最大的(造成影响最大)的X值进行变更,迭代进行,直到一个阈值停止。这个阈值就是我们前面提到的,保证程序基本功能没有发生变化。
作者在不同的恶意软件分类器上使用了对抗样本,都导致了较为显著的变化,即使是作者已经对对抗样本的修改进行了严格限制,仍然能让60%-80%的恶意应用程序误导分类器,不同分类器导致的错误结果如下。
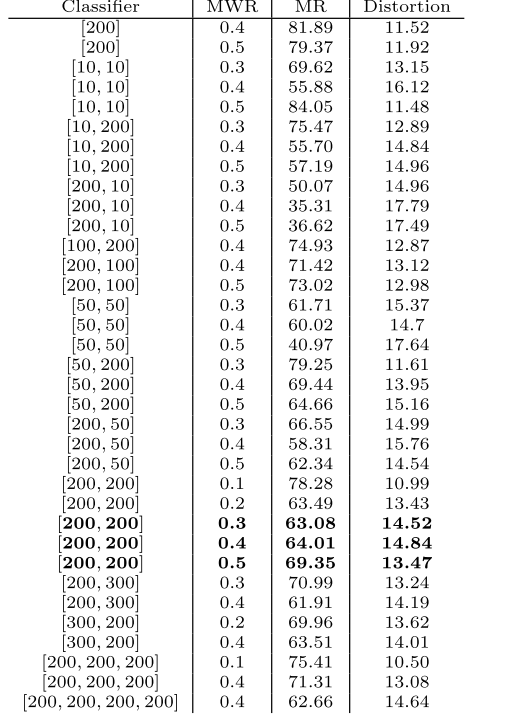
实际上,不同参数量的神经网络受到的影响也不相同,总的来说,MWR(恶意软件的所占比率)越高,对抗样本修改的功能数量接近的情况下,误分率越高。
从我个人在实验室做计算机视觉的研究经历来说,这个结果也确实是符合神经网络特性的。在图像领域,通过神经网络可视化,可以直接获得最后几层网络的高维特征,本质和人类识别物体的主要依据是类似的。回到恶意软件识别,正常的软件,就和识别物体一样,神经网络能迅速获得其高维特征,通俗来说,模型学习到的是不同正常软件中的共性,但是对于恶意软件,神经网络记忆的偏向于其中的特性,当恶意软件数据比例较大的时候,容易导致过拟合,分类效果反而会变得更差。这篇文章在恶意软件检测的领域,同样也得出了这一特性的表征。在软件安全领域使用神经网络模型,虽然导致了不少风险和争议,但是这一过程中也促进了对AI顶会中本来讨论较少的对抗样本的研究。
实际上,这篇文章被引用在了2018AAAI ARTIFICIAL INTELLIGENCE FOR CYBER SECURITY的一篇论文中。
该篇文章中提到,当前效果较好的神经网络恶意软件检测算法,主要是基于RNN的模型,将不同功能调用的API序列作为特征向量输入给RNN,在基本版本中通过隐藏层H1,H2…Hn,最终输出在两个类别上的概率分布。RNN与全连接和CNN的主要不同之处是在于它是考虑时序的,变体又包含了average-pooling,self-attention,bi-rnn,不同变体的应用场景略有区别,平均池化主要是考虑了每一个状态节点H的情况,即会考虑隐藏层的API序列状态,用自然语言处理的角度来进行说明的话,SELF-attention是Google一篇论文《attention is all you need》中提出的,本身是可以独立于RNN存在的时序模型,在和RNN结合后可以计算不同隐藏层之间的关联,RNN 机制实际中存在长程梯度消失的问题,对于较长的句子,我们很难寄希望于将输入的序列转化为定长的向量而保存所有的有效信息,所以随着所需翻译句子的长度的增加,这种结构的效果会显著下降,Attetnion 机制,正是为了解决这个问题而被引入的。即H1,H2….Hn之间的关系,这样的表述可能不够直观,我们以自然语言处理中的一个情况为例,简单说明self-attention 和 rnn的结合之后所产生的效果。
I arrived at the bank after crossing the river” I arrived at the bank after crossing the river” 这里面的 bank 指的是银行还是河岸呢,这就需要我们联系上下文,当我们看到 river 之后就应该知道这里 bank 很大概率指的是河岸。在 RNN 中我们就需要一步步的顺序处理从 bank 到 river 的所有词语,而当它们相距较远时 RNN 的效果常常较差,且由于其顺序性处理效率也较低。Self-Attention 则利用了 Attention 机制,计算每个单词与其他所有单词之间的关联,在这句话里,当翻译 bank 一词时,river 一词就有较高的 Attention score。利用这些 Attention score 就可以得到一个加权的表示,然后再放到一个前馈神经网络中得到新的表示,这一表示很好的考虑到上下文的信息。利用层层叠加的 Self-Attention 机制对每一个词得到新的考虑了上下文信息的表征。
说明了前两种RNN结构之后,双向RNN其实就是对正反两种时序的一种强化算法。我之前复现的一篇情感识别论文,采用的就是双向rnn加上self-attention机制,取得十分优异的识别效果。在本篇论文中,作者并不仅仅满足于寻找一个优秀的基于RNN的恶意软件检测模型,更是想通过RNN模型,进一步寻找更加优秀的对抗样本,挖掘这种软件测试模型中的漏洞。因此作者的核心工作,实际上是在了解了前述论文的对抗样本生成机制,又结合了当前的主流恶意软件检测RNN模型,提出了一种新的生成恶意软件检测对抗样本的方法。
该算法由生成RNN和替代RNN两部分组成,如下图所示
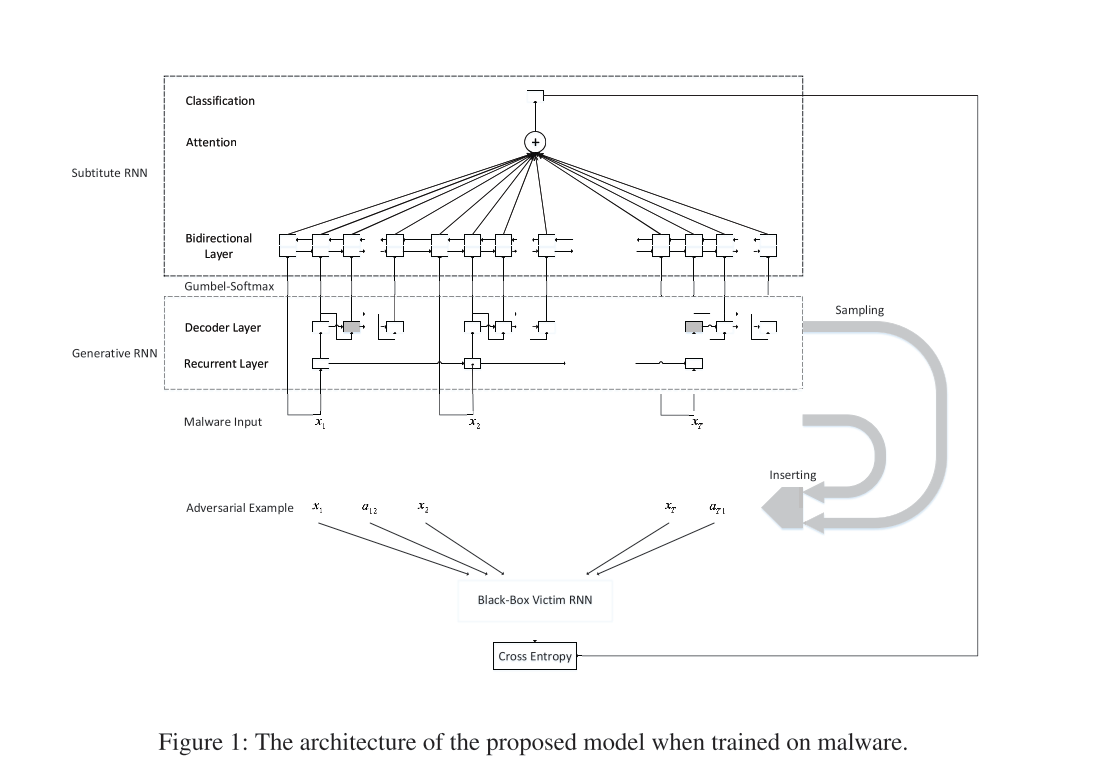
生成RNN输入的是恶意软件的API序列,输出是一小段API序列,之后将插入原有的API序列当中。需要注意的是,为了防止插入插入的API过多,在softmax层的向量中包含NULL API,如果被分类到NULL API则停止生成。另外一方面,由于API采样是非连续的,使用了2016《Categorical reparameterization with gumbel-softmax》中提出的Gumbel-softmax方法来获得梯度,公式如下:
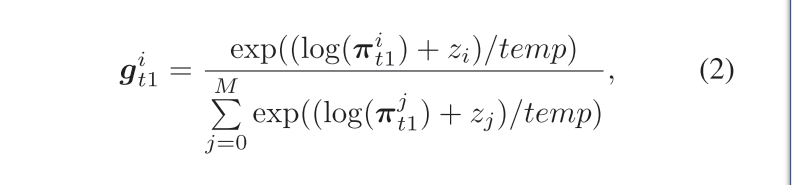
生成RNN目前只能随机地插入API序列,之后需要对其进行优化,使其生成插入点的API序列能更加有效地产生对抗样本。但是在实际情况下,要被对抗样本攻击的RNN,也就是本来用于恶意软件检测的RNN(后文简称为受害者RNN),其超参数和结构并不能轻易被恶意软件开发者所了解,因此我们需要伪造一个RNN,也就是我们前面说的,替代RNN,用于替代这个受害者RNN。因为受害者RNN的构造和权重未知,论文中采取了具有较强表示能力的RNN模型,即使用了前文所述的具有注意力机制的双向RNN,能够学习复杂的顺序模式。同样,为了模拟受害者RNN,训练数据应该同时包含恶意软件和正常软件。之后将gumbel-softmax输出的概率标签输入替代RNN进行分类,输出概率Ps,同时结合one-hot标签输入受害者RNN进行分类,获得一个二值标签和一个概率标签(符合实际中场景),然后采用交叉熵构成了损失函数进行优化,损失函数公式和优化流程如下图。

论文作者从网上获取了18万个含有相应API序列报告的数据,https://malwr.com。用户可以在这个网站上传程序,然后该网站会在虚拟机中执行,将API序列发布在网站,约70%使恶意软件。API序列的平均长度为10578,RNN在处理过长的序列时会消耗大量的计算资源,作者发现删除其中循环冗余的API不会影响恶意软件检测,做了相应的截断进行预处理,截断后的序列长度为1024.。
在数据集上训练和测试后作者发现,使用注意力机制的RNN模型效果更好,正如前文所说,注意力机制确实学习到了序列中不同部分的相对重要性,以
下是不同受害RNN模型被攻击前的准确率,很明显可以看出注意力机制起到了良好的效果。
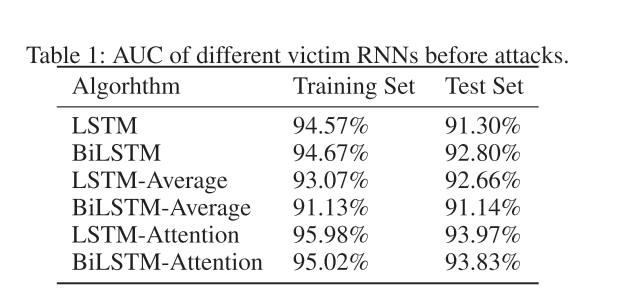
在训练好生成RNN和替代RNN后,生成了相应的对抗样本,在对抗性攻击后,所有的RNN都受到了巨大影响。
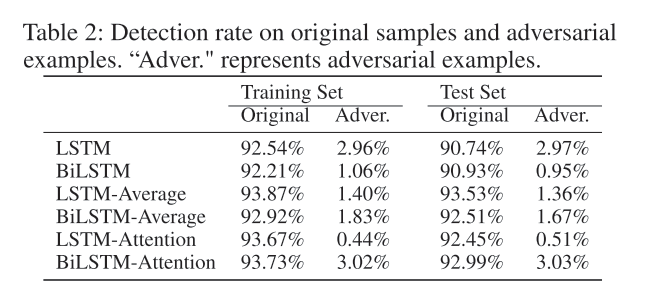
对抗样本的检出率最高只有3.03%,而在对抗攻击前,检出率最高高达93.87%。也就是说,在作者生成的对抗样本前,恶意软件检测RNN几乎完全失效。不过相比16年的攻击论文,该篇论文对插入API的限制较为宽松,因此可能会有夸大的效果,但是恶意检测RNN模型的脆弱性,从中也可见一斑。总的来说,本文给当前流行的恶意软件检测RNN模型敲响了警,算法设计者在不断提高神经网络模型在恶意软件的检测的效果的同时,也需要对这类对抗攻击有所防范。
版权属于:nicohime
本文链接:http://nicohime.com/archives/44/
转载时请注明出处及本声明