本文编写于 2327 天前,最后修改于 2327 天前,其中某些信息可能已经过时。
这是一篇2019年9月新的论文发表在IEEE上
具体分析暂时来不及写,对其主要创新点和实验做了一些分析在此简要记录一下。以及和2018年interspeech的进行了一些对比
创新点
我们之前也有想过这个方法,把频谱图的特征和声学特征进行融合,这是一个比较容易想到的思路,这篇文章主要是针对这个思路做的实现,需要注意的是这篇文章是在特征层面进行的融合,而不是在决策层进行,共用同一个损失函数进行优化。作者比较发现比起决策层进行融合,特征层融合效果更好。
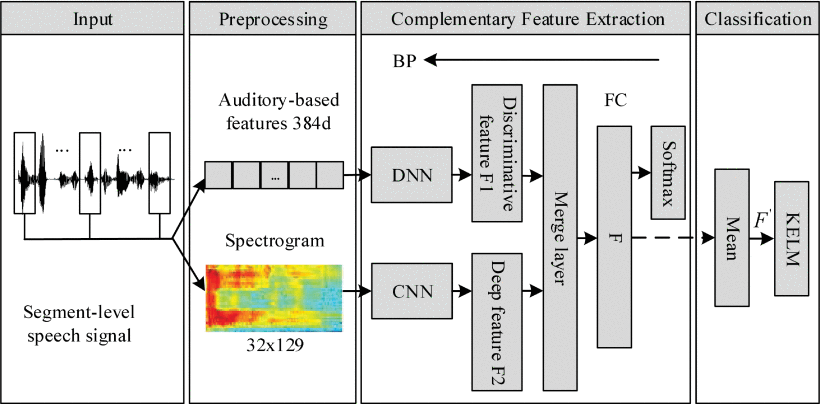
实验方面
这篇论文在两个常用语音数据集Emo-DB和IEMOCAP都进行了实验。
- Emo-DB数据库包含10位德国演员(5位女性/ 5位男性)产生的情感话语;他们使用不同的情感表达方式,阅读了日常对话中典型的10个预选句子之一。该数据库包含535种德语发音,其中包含7种情绪:愤怒,无聊,恐惧,厌恶,幸福,悲伤和中立。所有语音均以16 kHz采样,大约2–3秒长。
- IEMOCAP数据库是语音情感识别中最常用的语料库之一。该数据库包含大约12个小时的视听数据,包括10位熟练演员执行的视频,语音,面部动作捕捉和文本转录。所有语音都以16 kHz采样,大约3–15秒长。互动中来自每个参与者的每个话语都经过以下三个类别的分类评估:愤怒,快乐,悲伤,中立,沮丧,激动,恐惧,惊讶和厌恶,这是由三个不同的人标签。
同2018年interspeech一致,由于三个标签者可能为话语提供不同的标签,因此在本文的实验中,他们也只使用至少2个标签者标注一致的数据。
为了验证声学特征和图像特征确实对识别有帮助。作者使用t-sne对特征降维后进行了可视化分析,结果如下
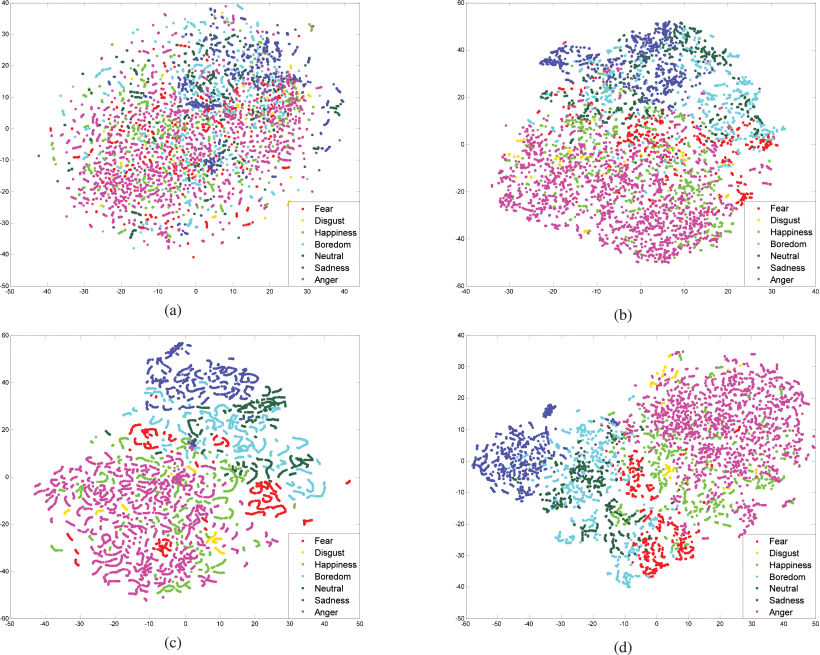
分析可以看出确实在加入图像特征后,提高了判别性。但似乎从准确率方面,在IEMOCAP数据集上,相较于2018年的论文并未有提升,暂时还未发现数据处理上有明显区别,具体还有待分析。
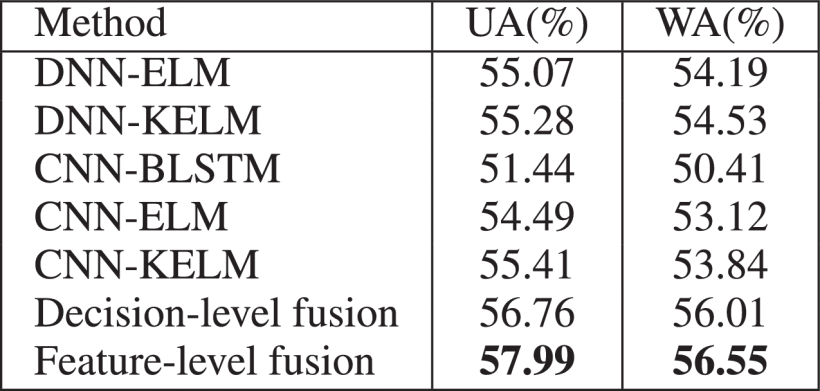
这篇文章同样也是较大提升了happy的准确率,也存在大量happy误认为angry的情况,给出的解释是能量特征比较相似,和我们实验中的观察一致。但是对于angry较少误认为happy的解释是数据库中angry占比较大我觉得值得商榷,我们实验中各类情绪数据基本均衡,同样存在这个问题。
附一张摘自其他博客的对比表,后续我也将制作相应的对比结果
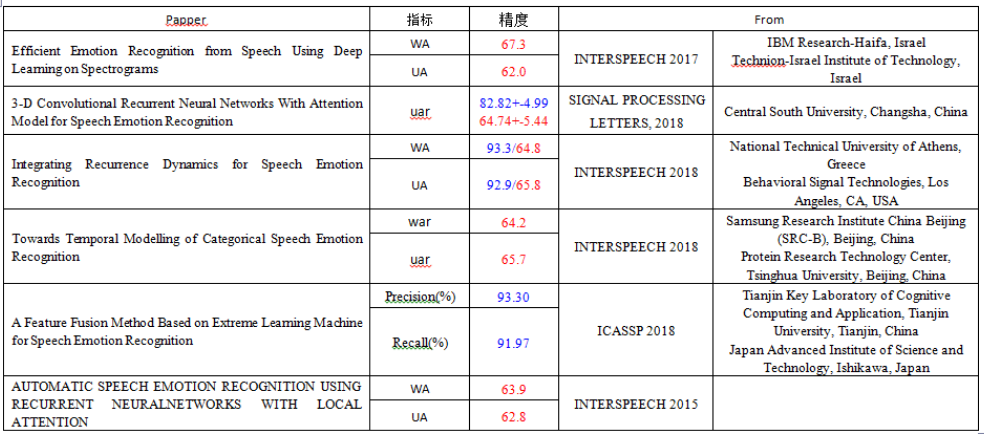
数据来源
版权属于:nicohime
本文链接:http://nicohime.com/archives/27/
转载时请注明出处及本声明