This article is an analysis of a paper publishied on Proceedings of the Annual Conference of the International Speech Communication Association, INTERSPEECH.In order to better accomplish our paper,I will retain doing reserach on relative work which can be reference to our job.I will analyze the paper from following aspects.
Now let's begin.
INTERSPEECH
INTERCSPEECH is a conference of the International Speech Communication Association (ISCA), which brings together a truly interdisciplinary group of experts from academia and industry to present and discuss the latest research.
Author
Ma, Xi
Wu, Zhiyong
Jia, Jia
Xu, Mingxing
Meng, Helen
Cai, Lianhong
Tsinghua-CUHK Joint Research Center for Media Sciences, Technologies and Systems,
Graduate School at Shenzhen, Tsinghua University, Shenzhen 518055, China 2Department of Systems Engineering and Engineering Management, The Chinese University of Hong Kong, Shatin, N.T., Hong Kong SAR, China 3Tsinghua National Laboratory for Information Science and Technology (TNList),
Department of Computer Science and Technology, Tsinghua University, Beijing 100084, China
Date
2018-September
Data
IEMOCAP.It contains these kinds of labels----happy, sad, neutral, angry, surprised, exited, frustration, disgust, fear and other.But the author mainly foucus on four emotion,Angry, Happy, Sad and Neutral,for they reach a majority agreement which means that at least two out of three evaluators gave the same label.
Abstract
This paper is about emotion recogniton.In my opinion, it didn't focus on the frame of emotion recognition,but mainly concentrated on the former work.In fact,it did splendid innovations.As we know,it is a common and useful way to turn video recording into spectrograms through DFT.This paper do the same work and then use CNN to exstract the patterns.Then use RNN to exstract the patterns in the time scale,for cnn has trouble in extracting them which maybe a waste of time sequence information.(Personal view).This is the figure of the frame of the neutral network .

Details
- Because of the padding of the data, the neutral network needs capacity to avoid the interference of padding value on the output. Let S = [x1, x2, ..., xV, ..., xT] be a input sequence, where S1 = [x1, x2, ..., xV] is the valid part and S2 = [xV+1, xV+2, ..., xT] is the padding part.So theny use a Mask Matrice to eliminate S2.Just simple multiplication will work.
- Take care of the border value between the valid part and the padding part, because max-pooling layer might compute valid part and padding part together.Then it will be a half value of the valid part which we don't want to see.
- In the bi-directional recurrent neural network, the output of backward recurrent neural network should be at t = 0. The final output is the concatenation of the outputs in forward and backward recurrent neural network.
- No padding is used during predicting stage.Padding into the same length with zero in the same batch during training stage, but the length between different batches are different.
Be ware of them when remake their experiments
Experiment
They ensures that the length of sentence doesn’t affect the bias of model by assigning
different weights to the loss----inverse proportion to the length.Be ware of it when remake their experiments.If you use balanced data in each category,you shouldn't do that
Results as below,
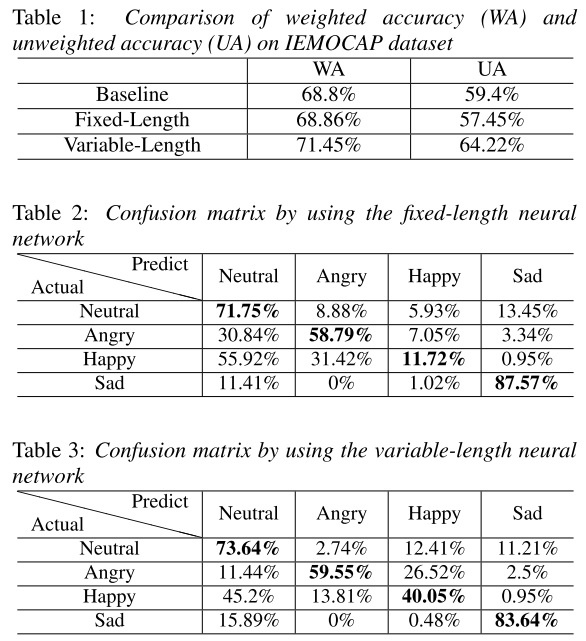
Analysis By Authors
The accuracy of Happy is improved significantly. This is caused by the neutral speech segment in the Happy sentence may be misclassified to other emotions, because these neutral speech segments are very similar by using fixed-length model. Meanwhile, the accuracy of Sad is decreased. It may be that the increasing recall of other non-neutral emotions lead to the decreasing recall of Sad.
Main Innovation
Use varibale-length segments replace fixed length segements in training.Develop some methods to avoid interference when using variable-length segments in training duration.(Mentioned in details).And what's important, it mention a resonable explanation in the problem that most of researchers have met int this quesion,that is, why happy is has the lowest accuracy.However,it is still less evidence that can directly prove this explanation is true.
欢迎大佬们交流指正
如果你也喜欢sakura,那我们就是朋友了
版权属于:nicohime
本文链接:http://nicohime.com/archives/23/
转载时请注明出处及本声明