这是对一篇京都大学论文的分析与复现,该论文发表在Interspeech 2019,内容和我们研究相关,同样也是做情感识别,未使用声学信息,从语谱图的角度进行分析处理。
既然是分析+复现,因此这篇会讲的比较详细,也会给出相应代码,暂且先用中文写吧,也想说些这过程中遇到的问题和技术,估计会蛮长的,后面有时间就用英文做一个没有这些废话的综述2333。
本篇为Chapter 1,不讨论公式及代码,主要以介绍论文使用的技术,为什么采用了这些方法,和我认为这些方法在语音识别中有效的原因。
论文简介与杂谈
言归正传,INTERSPEECH在某乎上被不少人认为是灌水会议,属于ccfC类会议,但是实际上语音方面比较被认可的会议,也就是ICASSP和INTERSPEECH了。事实上,在国外认可度还是蛮不错的,这也是为什么最后决定选择了这一篇作为论文的一个对比实验的原因之一。
另一方面呢,语音识别领域,单纯的一维语音信号其实已经能达到相当不错的准确率,目前准确率特别高的论文基本都是采用语谱图和语音信号相结合的手段,我们的方法仅使用了语谱图,和这些论文不好比较,
核心创新点与实际效果
总的来说,这篇文章的核心创新点其实现在已经在不少深度学习任务中得到实践和应用了,本质上说就是在CNN+LSTM的基础上(这是2017年的一篇论文提出的思路)加上Self Attention层和Multitask Learning(废话,论文题目就是这么说的。
先聊聊CNN+LSTM吧,因为使用的仅有语谱图,因此CNN结构是必需的,需要用CNN来提取高级别的特征,降低参数量。而LSTM呢,目前广发应用于各种NLP任务,因为他能很好的处理时序信息,而语谱图的是从一维语音信号转化而来,纵轴表示频率,而横轴依然表示时序,因此,使用lstm结构,可以有效利用语谱图中的时序信息。
那么新加入的元素,究竟是如何提升这已经看似全面的网络的呢?
Multitask
先说Multitask,多任务的核心是将输出层一分为二,在loss上的表现为和的形式,优化神经网络时同时要考虑两个目标,在这篇论文中,其中一个任务就是情感识别,共有四类,Angry,Happy,Neutral,Sad。另一个任务,是性别识别,woman,man。和大多是情感是别的论文一样,这篇论文用的时IEMOCAP数据集(如果不清楚数据集详情的话可以翻阅我之前的blog)。简单来说,这个数据集拥有的不止有情绪标签,同时也有性别标签。显然,我们很容易就可以想到,男女性在相同情绪,相同语言的情况下,语音信号的特征也是不相同的,因此,如果能利用上性别这一标签,多了一种判别特征,自然能提高情绪识别的准确率。
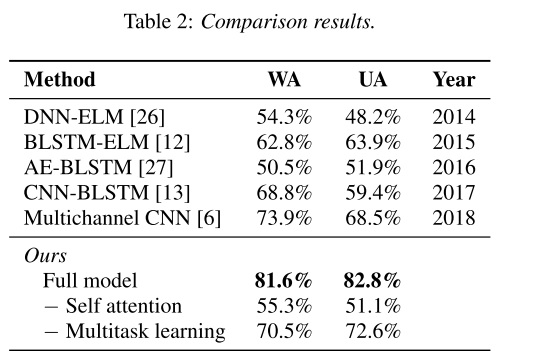
实际上,提升确实是相当明显的,在论文的对比实验中,去掉Multitask这个结构再做识别,论文在IEMOCAP上的准确率降低了约10%。
Self-Attention
这篇文章用的是Self-Attention机制,是在Attention的基础上做了一些改动,所以我先简单介绍一下Attention。
RNN机制实际中存在长程梯度消失的问题,对于较长的句子,我们很难寄希望于将输入的序列转化为定长的向量而保存所有的有效信息,所以随着所需翻译句子的长度的增加,这种结构的效果会显著下降,Attetnion机制,正是为了解决这个问题而被引入的。
Attention其实模拟的是人脑的注意力模型。举个例子来说,当我们阅读一段话时,虽然我们可以看到整句话,但是在我们深入仔细地观察时,其实眼睛聚焦的就只有很少的几个词,也就是说这个时候人脑对整句话的关注并不是均衡的,是有一定的权重区分的。
我们先以自然语言处理为例,
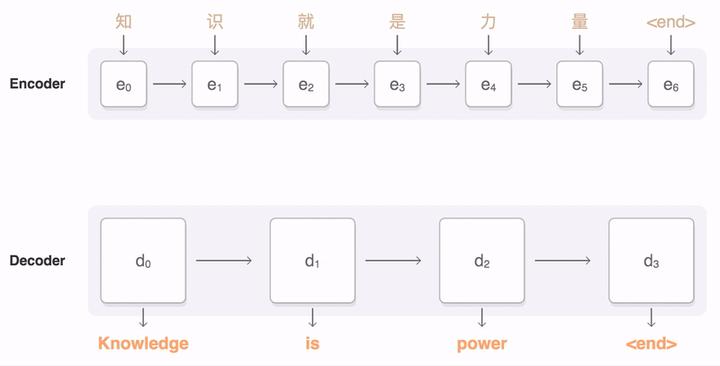
encoder与decoder是一个机器翻译模型,中间采用了Attention层做连接。我们从图中可以看到,经过Attention层之后,d0的Attention主要放在了e0和e1上,d1的Attention主要在e2,e3上,以此类推。可以发现,在翻译句子的时候,经过Attention结构后,生成了一个权重矩阵,对不同位置的词语赋予不同的权重。这就是前面提到的,人类翻译时,对整句话关注不是均衡的,是有一定权重区分的,可以有效提高翻译效率和效果。
如果单纯只使用encoder+decoder模型的情况下,会是怎么进行翻译的呢?
encoder 会按顺序依次接受输入,可以认为 encoder 的输出包含有词序信息。所以一定程度上 decoder 的翻译也基本上沿着原始句子的顺序依次进行,但实际中翻译却未必如此,以下是一个翻译的例子:

我们对Attention的大致思路和框架有了一个了解之后,我们现在来看看Self-Attention,Self-Attention其实是一种为了避免使用RNN的hidden state而做的研究和实现,原因是作者觉得RNN一跑就要好几天,实在是太慢了2333。

这是完整的模型图,是不是看起来特别复杂2333,作者骄傲地宣称他这套 Transformer 是能够计算 input 和 output 的 representation 而不借助 RNN 的唯一的 model,所以作者说有 attention 就够了。

我只能说,不愧是Google。
回到正题,我做的分析并不是针对Self-Attention,实际上,京都大学的这篇论文中,还是使用了LSTM结构,但是Self-Attention的思路其实已经体现了出来,
还是以自然语言处理为例,
Self-Attention利用了Attention机制,计算每个单词与其他所有单词之间的关联,
I arrived at the bank after crossing the river” I arrived at the bank after crossing the river” 这里面的bank指的是银行还是河岸呢,这就需要我们联系上下文,当我们看到river之后就应该知道这里bank很大概率指的是河岸。在RNN中我们就需要一步步的顺序处理从bank到river的所有词语,而当它们相距较远时RNN的效果常常较差,且由于其顺序性处理效率也较低。Self-Attention则利用了Attention机制,计算每个单词与其他所有单词之间的关联,在这句话里,当翻译bank一词时,river一词就有较高的Attention score。利用这些Attention score就可以得到一个加权的表示,然后再放到一个前馈神经网络中得到新的表示,这一表示很好的考虑到上下文的信息。如下图所示,encoder读入输入数据,利用层层叠加的Self-Attention机制对每一个词得到新的考虑了上下文信息的表征。Decoder也利用类似的Self-Attention机制,但它不仅仅看之前产生的输出的文字,而且还要attend encoder的输出。以上步骤如下动图所示:(摘自https://zhuanlan.zhihu.com/p/47282410
从这张图我们可以看到,不同词对当前词的线粗细不一,其实就是代表权重不同。

现在再看京都大学的这篇论文,我们就能很容易明白,cnn+lstm的基础上加上Self-Attention和Mulittask可以起到非常好的效果。前文我们已经提到了cnn+lstm的作用,和自然语言处理一样,在情感识别中同样也需要考虑前言后语流露出的情感对当前语境的影响,同样,前言后语间的情绪对当前情绪判断的影响,也是不相同的。因此,在原文的对比实验中,去掉Self-Attention结构后,准确率降低了25%左右,影响远大于Multitask的10%。
以下是原文对比实验结果
相关的实现代码与公式推导,我会在下一节给出实现和分析,这篇写的有点长了,需要注意的是文中使用的self-attention并没有抛弃RNN,因此相对来说没有那么复杂,但是原理和思想是一致的。
PS:刚才出了个bug,把最后的综述和图片都给搞没了,我只想把忘记加的音乐给补上而已啊。因此呢,最后的综述可能会相对简略一些,也不知道还有没有其他谬误
欢迎大佬们批评交流~
参考链接:
- https://qiita.com/itok_msi/items/ad95425b6773985ef959
- https://www.jiqizhixin.com/articles/2018-06-11-16
- https://zhuanlan.zhihu.com/p/47282410
- https://www.zhihu.com/question/68482809
- https://arxiv.org/abs/1706.03762
- https://github.com/nn116003/self-attention-classification
あなたの読むことに感谢します
版权属于:nicohime
本文链接:http://nicohime.com/archives/38/
转载时请注明出处及本声明
Thanks a lot for giving everyone such a splendid chance to check tips from this blog. It is usually very beneficial and also packed with a good time for me personally and my office acquaintances to search your blog at a minimum three times in one week to read the latest guides you will have. Not to mention, I am just actually satisfied for the brilliant secrets you give. Some 2 ideas on this page are honestly the most suitable I have had.
golden goose 2020-11-14 18:39
I actually wanted to compose a small word to appreciate you for all of the wonderful tips and hints you are sharing on this site. My time consuming internet look up has finally been honored with good quality ideas to write about with my family. I 'd state that that many of us visitors are very fortunate to dwell in a fabulous site with many marvellous people with great tactics. I feel truly grateful to have come across the webpages and look forward to some more cool moments reading here. Thank you once again for all the details.
bape hoodie 2020-10-20 07:50
博主你好,我最近也在做这篇论文的复现,不过和预期结果相差很大,方便的话可以和您交流一下吗,我微信ljw15137090793 QQ2319277867
LJW 2020-03-27 23:40
我们用的是自己的数据集,相同方法准确率基本都有下降,单纯用lstm+cnn也比17年的低了不少,现在主要是因为我们的数据集里没有弄性别标签,所以换了另外一篇论文做对比实验。不然缺少多任务,被评审人质询的概率比较高
你可以试试调整看看attention nodes,这个参数的选取论文中没有给出明确理由,实际上在我们数据集上用的时候,我测了8和1,一个的准确率反而略高一些
nicohime 2020-03-28 18:37
他论文中用到了消解学习,只使用情感分类类损失作为loss,可以达到70.0%+的正确率,但是我按他的方法只能达到58%左右,不知道是不是哪方面出了问题 -_- ,我按您说的head nodes设为1,测试了一下发现好像没什么影响。
LJW 2020-03-29 17:01
这确实有点难排查,我这边因为这篇用不了,在复现18年的另一篇论文,也有一些玄学问题,这篇赶完之后可能会再把这个研究清楚一下
nicohime 2020-04-01 16:43